Introduction#
![]()
Basics in linear algebra and calculus
Basics in python
Definitions: bias, variance, irreducible error, underfitting, overfitting
Introduction to probabilistic machine learning
The IPCC report#

The working group 1 (WG1) of the Intergovernmental Panel on Climate Change (IPCC) is a group of scientists who assess and quantify climate change. In order to provide an accurate description of the future climate, they use numerical models also known as Climate Model Intercomparison Project (CMIP).
There are many components in a climate model: the main two parts are the oceanic model and the atmospheric model. Both models predict the evolution of state variable (temperature, velocity, CO2, etc.) on predefined grid points. In order to get an accurate prediction of the CO2 concentration, we also need to have a specific model to capture the dynamics of living ecosystems and biogeochemical cycles. In polar regions there are specific models for ice sheets and sea ice.
There are several scenarios (Shared Socioeconomic Pathways) ranging from very optimistic (SS1: sustainability) to (very) pessimistic (SS5: Fossil fuel development)
In CMIP6, there are over 100 full blown models that attempt to propose the most reliable forecast for each of these scenarios Balaji et. al (2018)
Dealing with all model outputs is not a sinecure. To write the IPCC report , thousands of scientists collaborated to share their data, produce consistent diagnostics and plot an overview of what all these models are telling us. The main point of this model intercomparison is to reduce the uncertainty of the prediction of the future climate. It is indeed very important to know:
how much of global warming has human origins (understand the climate system)
if tipping points will be crossed in 2030 or 2050 in order to best anticipate the changes (do predictions).
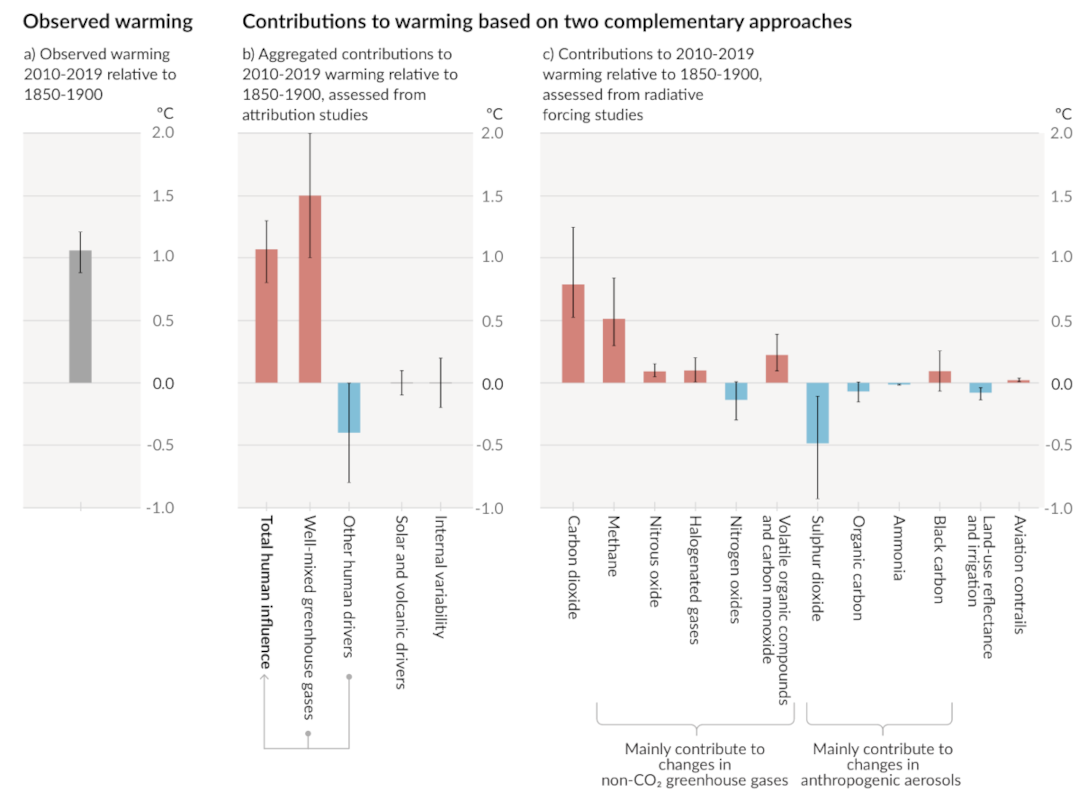
Figure SPM2 (IPCC repport)
The figure above is a summary of the causes of the 1 degree temperature change since the industrial revolution. In this problem, there is one output variable (global temperature) and many input variables (CO2, methane, etc…). We sometimes call the input variable the independent variables and the output variable the dependent variable as the latter is function of the input variables.
The problem highlighted in the figure corresponds to a typical machine learning problem where we want to find a function that maps the input variables onto the output variables.
First problem: variation of temperature with altitude#
Before we solve the climate problem, let us start with a simpler question. You may have noticed that as you climb a mountain temperature gets cooler: you may even reach heights where there is permanent snow and ice. In order to get more insight on the vertical temperature profile in the atmosphere, meteorologist have used radio sounding. A adio sounding consists in launching a buoyant balloon filled with hydrogen or helium to which we attach a weather station. The buoyancy force drives the balloon upward and the instruments attached at the base of the balloon record variables of interest such as pressure, temperature, humidity, altitude, etc. Below is a short clip of the launch of a sounding at the strateole campaign at the Laboratoire de Meteorologie Dynamique. Let’s use the data of these soundings to see if we can extract a general law for the variation of temperature with height.

import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
df_960901 = pd.read_csv('data/soundings/07145.19960901000000.csv', na_values='mq',skiprows=2)
ax = df_960901.plot('geop','t',style='+',label="T (1996/09/01)")
ax.set_xlabel('Height (m)')
ax.set_ylabel('Temperature (K)')
Text(0, 0.5, 'Temperature (K)')
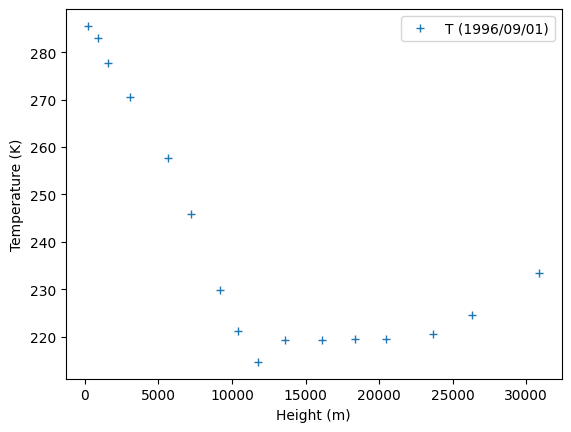
The temperature decreases from the surface to roughly 10 km. Above that altitude, the temperature increases slightly. The atmospheric layer from the ground to 10 km corresponds to the troposphere. In this layer, we would like to propose a physical law for the variation of temperature with altitude. As a first guess, we suppose that there exist a linear relationship between the temperature and the altitude
with \(y\) the temperature and \(x\) the altitude. \(\alpha\) is called the regression coefficient and \(\beta\) is called the intercept. In the next chapter, we are going to study linear regression and see how we can find \(\alpha\) and \(\beta\).
Although linear regression seems extremely simple, it is still regarded as the model of maximum interpretability. In fact, the sign and the magnitude of \(\alpha\) tell you how \(y\) varies with \(x\) in an unambiguous way and you can easily confront this result to your physical intuition. In our case, \(\alpha\) will tell us how many degrees we loose per meter traveled upward.
Later on, we will study neural networks with millions of parameters which may give a better prediction for \(y\) than the linear regression. However, if neural networks give better predictions, their prediction is sometimes hard to interpret. Needless to say that it is important to try simple methods first before going to more complicated algorithms… Even if simple models are sometimes too simple.
# prepare dataset: limit height to h_max and drop missing values
h_max = 13000
X = df_960901['geop'][df_960901['geop'] < h_max].dropna().values
y = df_960901['t'][df_960901['geop'] < h_max].dropna().values
# create feature matrix
A = np.vstack([X, np.ones(len(X))]).T
#linear regression with numpy
m, c = np.linalg.lstsq(A, y, rcond=None)[0]
# plot original dataset and linear fit
ax = df_960901.plot('geop','t',style='+',label="T (1996/09/01)")
ax.set_xlabel('Height (m)')
ax.set_ylabel('Temperature (K)')
ax.plot(X, m*X + c, 'r', label='Linear fit')
plt.legend()
print(f"According to the linear fit, the temperature gradient is {m:.3e} degree/m")
According to the linear fit, the temperature gradient is -6.259e-03 degree/m
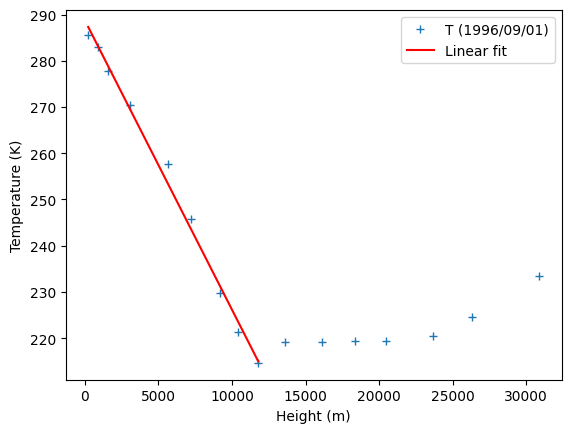
According to the linear fit, the temperature gradient is -6 degree/km. There is actually a physical justification to explain the variations of temperature with height. With thermodynamical arguments, we can show that the variation should be on the order of 5 degree/km. It is called the (moist) adiabatic lapse rate.
Questions
How robust is this fit?
Would we get the same fit if we were to launch another balloon right after this one? 3 hours later? 3 days later? one year later?
In the folder data/soundings we provide 2 more soundings for the dates 1996/09/03 and 1997/09/01. Don’t hesitate to try to plot it to visualize the amplitude of the variability.
In machine learning problems, the task is to propose an estimate of the function that predicts the output variable based on the known input variables. This is based on our intuition that there is a relationship between the input and output variables in the form of
with \(f\) the function that we will try to guess and \(\epsilon\) is an Irreducible error that can have multiple origins.
Questions
Give several sources of errors for the problem we are considering
In this framework, \(\epsilon\) is really an irreducible error. However, if you add more input variables, can you reduce the amplitude the irreducible error?
The above equation is the ground truth, however we usually don’t know \(f\). Our task is to propose an estimate of \(f\) based on the sample observation that we have. Because our observations are limited, we can only approximate \(f\): we will denote this approximate function with a hat and write our prediction as
Note that this equation is deterministic: there is no random noise in the right hand side. In fact, because we want to provide the best estimate, there is no need to add noise in the prediction: that would necessarily give a worse prediction for \(y\) (cf. next chapter)
We can then use \(\hat f\) to
make predictions
understand the relationship between input and output variables
These two objectives are at the heart of machine learning techniques.
In the case of the linear regression, the function \(f\) has two unknown parameters \(\alpha\) and \(\beta\). We call these functions parametric functions and the machine learning exercise consists in finding the best values for these parameters. There exists also functions \(f\) that do not depend on any parameter (such as the spline fit). These functions are called non-parametric functions.
Probabilistic perspective#
In the formalism that we have just discussed
the output variable \(y\) is a random variable, and the input variable \(x\) is an observation that is given without uncertainty. We can adopt a probabilistic approach to describe what the \(f\) function could be. Suppose that \(f\) is a parametric function with parameters \(\alpha\) and \(\beta\) (for the case of the linear regression). In order to use compact notation, let us gather all parameters in a vector \(\mathbf{\theta}=(\alpha, \beta)\) Then a machine learning problem consist in finding the parameters \(\mathbf{\theta}\) such that the probability
is maximum. Because we know \(y\) and we vary \(\mathbf{\theta}\), we call this quantity the likelihood of \(\mathbf{\theta}\) given \(y\), and our goal is to find the values of the parameters that maximize this likelihood.
In order to derive an analytical solution to this problem, we have to make assumptions about the noise \(\epsilon\). In the most simplest case, we assume that \(\epsilon\) is a Gaussian noise with zero mean and variance \(\sigma^2\):
Hence
In fact, we have \(N\) observations \(\mathcal D = \{(x_1,y_1), ... (x_N,y_N)\}\). Met us call \(\mathcal X = \{ x_1, ... x_N\}\) the set of input variable and \(\mathcal Y = \{ y_1, ... y_N\}\) the corresponding set of output variable. Then, we want to maximize the likelihood
We further assume that all observations are independent and identically distributed such that
Remember that we want to find the values of \(\mathbf{\theta}\) that maximizes this likelihood. Because we have assumed Gaussian noise, it make sense to find the maximum of the logarithm of \(p(\mathcal Y|\mathcal X,\mathbf{\theta})\) (because the probability is a Gaussian distribution). Taking the log also transforms the product of all probabilities to a sum with is easier to handle for the minimization procedure.
With all these assumptions, we get a closed form solution for the values of parameters (see Chap. 9.2 in Mathematics for Machine learning for a detailed derivation). The value of \(\mathbf{\theta}\) obtained with this method is called the Maximum likelihood estimate (MLE). In the next chapter, We will find the solution for \(\mathbf{\theta}\) with a non-probabilistic method.
Types of errors#
There are 3 types of errors:
Bias error
Variance error
Irreducible errors.
We want to find model that have both the lowest bias and lowest variance. The irreducible error is intrinsic the dataset.
Questions
How do we know that \(\hat f\) is the correct fit?
If we do a second field campain and take more measurements, will we get a new estimate for \(\hat f\)?
What if we use more precise instruments to do the measurements?
Suppose we now want a general law for the variation of temperature over the whole atmosphere - and not only the troposphere. Clearly, a linear fit will be a poor estimate.
Question
Try to adjust
h_maxin the linear fit above to perform the linear regression over the whole atmosphere
In this case, the function \(\hat f\) is not so good. In order to quantify how good, or how bad the model is, we need to introduce a metric. Example of such metric is the mean squared error
Hence, \(\sqrt{L}\) is the typical error you do when you use the model \(\hat f\) to make a prediction for \(y\). Of course, we wish to have \(L\) as small as possible. This type of metric is also called a Loss function or a cost function and a typical machine learning task is to minimize the loss function. It is sometimes possible to do it analytically for simple problems but most of the time we use numerical algorithms to find that minimum.
Bias error#
If the model we are trying to fit does not have enough degrees of freedom, there is a risk that we are underfitting the data, which is characterized by the Bias error. We say a model is biased when it is not able to capture the correct relationship between features and target output. In the example above, we were trying to fit a linear relationship for the temperature over the whole atmosphere, but the relationship between the input and output variables was clearly not linear. The model is biased because there will always be an offset in the prediction of the output variable.
Formally, the bias error is defined as
which corresponds to the systematic misfit between our prediction and the data.
Variance error#
An easy fix is to choose a different function \(f\) and make it as complicated as we want so that this function goes through all our sample points. For our temperature profile, we have 15 points such that a polynomial of order 15 could work:
Remark: this type of function still falls in the linear regression category because it is linear for the parameters \(\mathbf{\theta} = (\alpha_1, ... \alpha_{15}, \beta)\). The input features are now powers of \(x\): \((x, x^2, ...,x^{15} )\), but all the formalism developed for 1D models can actually be written in vector form to handle the situation where the input variables are multivariate.
h_max = 30000
X = df_960901['geop'][df_960901['geop'] < h_max].dropna().values
y = df_960901['t'][df_960901['geop'] < h_max].dropna().values
# polynomial order
p_order = 15
p_coefs = np.polyfit(X, y, p_order)
p = np.poly1d(p_coefs)
xp = np.linspace(X.min(),X.max(),500)
plt.plot(X,y,'+', label='Sample data')
plt.plot(xp,p(xp),'-', label='Polynomial fit')
plt.ylim([200,300])
plt.legend()
plt.xlabel('Height (m)')
plt.ylabel('Temperature (K)')
plt.legend()
/builds/energy4climate/public/education/machine_learning_for_climate_and_energy/venv/lib/python3.8/site-packages/IPython/core/interactiveshell.py:3508: RankWarning: Polyfit may be poorly conditioned
exec(code_obj, self.user_global_ns, self.user_ns)
<matplotlib.legend.Legend at 0x7f00dc42cdf0>
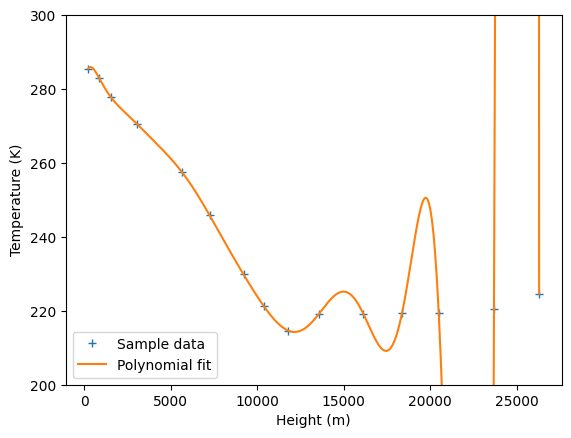
Indeed, this model has the lowest possible loss function \(L=0\). However, we identify at least three drawbacks:
this function has poor predicting skills away from the sample points.
any modification of the dataset might cause big modifications in \(\hat f\).
the physical interpretation is limited
One way to quantify the uncertainty on \(\hat f\) is to divide the data set in a training data set and a testing data set. We use the training data set to compute \(\hat f\) and with the help of a metric, we can give a score to that \(\hat f\) to compute how well it performs to reproduce the output variable.
Then to validate the model, we compute the same score on the testing data set. If the score is the same than for the training data set, then the model is not specific to the training data set and can be generalized to more data. If the score is (significantly) higher, then that means the model is overfitting the data.
To measure how much the model is overfitting the data we introduce the Variance error which is a measure of the spread of all possible \(\hat f\) function that one could get with all possible samples that are available. A model with high variance will change a lot from one dataset to another. Such model is overfitting the data.
A very rough estimate of the variance error is thus given by
with \(L_{test}\) and \(L_{train}\) are the Loss function computed on the testing and training dataset respectively.
Irreducible error#
The last type of error we are going to deal with is the Irreducible error. This error corresponds to the \(\epsilon\) term in our model. You may see this error as the precision of your instrument or as missing physics in your model. This can be due to chaotic perturbation of your system. This type of error is not predictable.
Regularization (probabilistic approach)#
Of course, to reduce the variance error, it would have been a good idea to try a polynomial fit with lower order input features.
Question
Try to adjust
p_orderin the polynomial (linear) regression above.What would be your best choice for
p_order? why?
While it is is often a good idea to select the lowest possible order, there are some arbitrary decisions to guess what that order should be. Instead of choosing the order, we can add some constraints on the coefficients \(\mathbf{\theta}\) such that they remain within an acceptable range. For instance, one can choose the probability distribution of all \(\alpha_i\) to be
such that each coefficient \(\alpha_i\) will probably remain in the range \([-2\sigma,2\sigma]\). This procedure will limit the influence of the terms with high exponents because these terms have a tendency to have big coefficients. We say we put a prior on the coefficients. This means that before (prior) having seen any data, we impose a probability distribution on the coefficients. When adding a constraint on the parameters we say we regularize the problem.
By doing so, we actually turn the parameters \(\mathbf \theta\) into a random variable and we can use Bayes’ theorem to get the probability distribution on \(\theta\):
where we recognize the likelihood that we have been discussing earlier and the prior that we have just introduce. The denominator \(p(\mathcal Y|\mathcal X)\) is a normalization constant independent of \(\mathbf \theta\). The left hand side is called the posterior and is the quantity of interest here. We want to find the most probable values for the parameters \(\mathbf \theta\). The values of \(\mathbf \theta\) that maximize this probability are called the Maximum A Posteriori (MAP). If the likelihood and the prior are Gaussian, we can find the analytical MAP but the derivation is beyond the scope of this introduction. At this point, you should remember that regularization consist in adding constraint on the parameters in order to get a smoother function \(\hat f\).
Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs (labelled data set). The key aspect of supervised learning is that there exists a training data set with labelled data.
on the other hand, Unsupervised learning corresponds to the problem of guessing patterns in an unlabelled data set
References#
Credit#
Contributors include Bruno Deremble and Alexis Tantet.
