Classification I: Generative models#
![]()
Understand and apply Bayes Theorem
Define the Bayes decision boundary
Derive a Linear discriminant analysis to solve a classification problem
Define and Understand how to apply a Naive Bayses classifier to solve a classification problem
Introduction#
Weather, clouds, seasons, wind, hurricane… Categories and classifications are everywhere in environmental sciences. They can be artificially created based on thresholds (as in the hurricane example below) or they can correspond to truly discrete variable (e.g. “It’s raining, it’s not raining”).
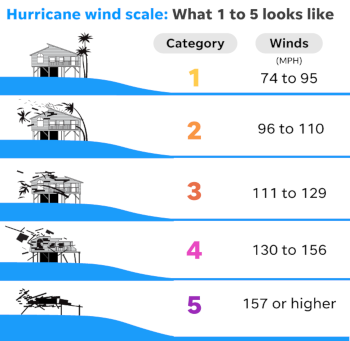
To use proper terminology, we say that categorical variables are qualitative (can be described with words) whereas variables that reflect a notion of magnitude are quantitative (can be measured).
In the example above, you can describe with words what a hurricane of category 3 is. However, you cannot describe what a wind of 100 km/h is.
Weather icons#
We have already derived methods to predict quantitative variables (variables that vary continuously).
In many problems however, the variable we are trying to predict is qualitative (takes discrete values).
Complex meteorological situation often summarized by a pictogram/a warning, e.g. Cat 5, hurricane, storm warning…
Helps establishing an appropriate response plan based on the forecast.
Illustration of the transition between quantitative and qualitative variables#

Figure: Weather map for a given day and the corresponding weather icons that one can use to produce a weather report.
Case study: Rain prediction#
- Predicting the rain remains a challenge.
- It results from multi-scale phenomena:
- from the large-scale organization of weather system
- to the small scale microphysics of dropplet formation.
- Dynamical models attempt to capture all these scales.
- Yet, apparent correspondance between surface pressure and weather.

Classification as a Supervised Learning Problem#
Setting up the problem#
Let
Problem: classify the current weather into a category
Example:
Let
We are given two categories:
Like regression, this is a supervised learning problem, but with a discrete target instead of a continuous one.
We want to learn the conditional probability distribution
Each
See Supervised Learning Problem.
The
Hence, there exists a joint Probability Distribution Function (PDF)
that describes how likely it is to observe weather
There also exists a discrete probability distribution
to observe either event
Question
What are the two conditions required for
to be a PDF?
Bayes Classifier#
Bayes classifier
The classifier that assigns to
Bayes classifier problem: For a given
Bayes Decision boundary#
Bayes Decision Boundary for 2 Classes
The set of points
i.e the part of the input domain for which the conditional probability of belonging to each class is equal.
Equivalent Bayes classifier problem: find this decision boundary.
Bayes Decision Boundary for
The boundary given by the union of the Bayes Decision Boundaries for all pair of classes
A First Classification Model#
Linear Classifiers
Classifiers for which the decision boundary is given by a linear equation in
Example: provide a classification rain/no rain given the pressure predictor
From our observations, we have an estimate of the probability of rain/no rain conditionned on pressure.
We plot the densities of these conditional probability distributions in the following figure.
Here, the direct estimation of the conditional PDFs is possible thanks to the low dimensionality of the input space (
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
plt.rc('font', size=14)
# figure inspired from https://www.astroml.org/book_figures/chapter9/fig_bayes_DB.html
def gaussian(x, mu, sigma):
return 1 / (np.sqrt(2 * np.pi) * sigma) * np.exp(-((x - mu) / sigma)**2 / 2)
pressure = np.linspace(-5, 10, 1000) # pressure distribution (fake units)
# Non-conditional probabilities
p_rain = 0.3 # that it is raining
p_norain = 1 - p_rain # that it is not raining
pdf_rain = p_rain * gaussian(pressure, -1, 1)
pdf_norain = p_norain * gaussian(pressure, 2, 2)
pressure_bayes = pressure[np.where(pdf_rain > pdf_norain)][-1]
def plot_rain_conditional_pdf(pressure, pdf_rain, pdf_norain, pressure_bayes,
ylim=[0, 0.15]):
plt.plot(pressure, pdf_rain, label='Rain')
plt.plot(pressure, pdf_norain, label='No rain')
plt.plot([pressure_bayes, pressure_bayes], ylim, 'k--',
label='Bayes decision point')
plt.xlabel('Pressure $x$ (fake units)')
plt.ylabel('Conditional probability')
plt.xlim(pressure[[0, -1]])
plt.ylim(ylim)
_ = plt.legend(loc=[1.03, 0.67])
plot_rain_conditional_pdf(pressure, pdf_rain, pdf_norain, pressure_bayes)

We see that :
when
when
The point
It correspond to the pressure
The Bayes classifier
Note however that:
there are days without rain for which
there are rainy days for which
The Bayes classifier
A Score for Classification#
Misclassification Probability
The misclassification probability, or risk, of the classifier
where
Proposition
The Bayes classifier minimizes the misclassification probability.
This is nice, BUT…
…applying the Bayes classifier requires knowing the true conditional probability distributions of all categories.
We do not know them in practice…
Bayes theorem#
Issue: The direct conditional probability
Idea: Use Bayes’ theorem to relate it to
Bayes theorem
for all
Caution with the likelihood#
Given
It is indeed a function of
However, at the end of the day, we are interested in finding
If we consider that
Question
We observe a temperature of the atmosphere of 3°C on a discrete scale. What does the likelihood of a rain/no rain random variable describe?
Does
and sum up to 1?
Prior#
The prior
Question
Can you relate the joint probability density
to and to show that the latter is a normalization factor in the Bayes theorem.
Generative models#
By applying the Bayes theorem, we have shifted from a problem of estimating the conditional distribution
But we still need methods to estimate the latter!
Generative Models
Classification models based on the estimation of the class densities
for all
Once we have a model for these densities, we can use Bayes’ theorem to infer the conditional probability distribution of the classes, namely
from which the decision boundary can be drawn.
Examples of generative models#
Linear and quadratic discriminant analysis (based on Gaussian densities),
more flexible mixtures of Gaussians to allow for nonlinear boundaries,
general nonparametric density estimates to provide more flexibility,
Naive Bayes models which are a variant of the previous case and assume that each of the class densities are products of marginal densities (conditional independence).
Linear Discriminant Analysis (LDA)#
Idea: Assume that:
all class densities
the classes may have different (
but they have a common (
for all
Case with 1 predictor (
First consider the case where there is only 1 input, that is
In LDA, we assume that, for each class, the data is distributed according to the Gaussian distribution
That is
LDA problem for
Learning LDA#
We are given a training set
To estimate the parameters
We gather all the observations that belong to a class
where the sums are over all the
The unbiased sample estimate of the variance can be written as a weighted average of the class variances
So, for all
Remember that we are interested in
Question
Given the training sample, what is
, the most obvious estimate of , the probability that an observation falls into the class ?
Computing the posterior distribution#
Given a new input
for all
Simplified classification using the discriminant function#
We know that, for a given observation, we can assign the class
Since the log is a monotonic function, we can also compare the log of the probability and get the same result for our classification.
In the case of LDA, this means that we can assign an observation to the class for which
is the highest.
This quantity is called the discriminant function.
Also,
Question (optional)
Derive the equation of the linear discriminant function.
We get that the discriminant is a linear function of
It is linear because all class densities
This causes the nonlinear term to cancel in the expression of the discriminant.
Generalization of LDA to
All the formalism holds in higher dimensions: the likelihood in a
where
For
This expression is very similar to the 1D case, except that we now handle vectors and matrices instead of scalars.
Pros and cons of LDA#
Pros: Few parameters to adjust (method not prone to overfitting).
Cons: Each class does not necessarily have the same variance nor follow the same parametric distribution.
Alternative: If we relax that approximation of equal variances, we get a decision boundary which is no longer linear: it is called Quadratic Discriminant Analysis (QDA).
Apply the Bayes theorem to inverse the problem (Generative model),
Assume multivariate normal class densities with common covariance matrix,
As a result, the decision boundary is linear.
Naive Bayes#
The Naive Bayes classifier is a popular method that share many similarities with LDA.
Like LDA, it is a generative model for which we try to estimate the class densities.
In order to estimate that probability, the naive Bayes methods naively assume that all variables are independent.
That is
for all
which we will need for the normalization in Bayes’ theorem.
This hypothesis of independent features is strong.
This method should not be used when strong dependences exist between features.
Classification of images, for instance, often fail because nearby pixels are correlated.
Still attractive:
because is is much simpler to estimate 1D marginal PDFs rather than
it is useful when the number of features
To estimate these marginal PDFs, we can use any method like Gaussian kernels, histograms, etc.
To go further#
Using Gaussian mixtures to model the class densities, leading to nonlinear decision boundaries (Chap. 6 in Hastie et al. 2009).
Using nonparametric density estimates for each class density (Chap. 6 in Hastie et al. 2009).
References#
Credit#
Contributors include Bruno Deremble and Alexis Tantet.
